● 머신러닝이란 용어가 이제는 낯설지만은 않습니다. 기계학습이라는 의미로 인공지능을 구현하기 위한 방법이죠. 컴퓨터가 학습하는 방식 혹은 그에 관한 연구를 총칭합니다.
● 현실 세계는 매우 복잡다단합니다. 그래서 모델이 필요합니다. 모델은 현실 세계의 본질이나 핵심을 나타내는 모형입니다. 이 모델을 만드는 작업을 모델링한다고 표현합니다.
● 단순화 즉, 모델링은 여러모로 유익이 있습니다. 물론 너무 단순화시키면 언더 피팅되어 현실을 충실히 반영하지 못하게 되지만, 적정하게 단순화한다면 계산 복잡도를 줄여주어 수학적인 해결을 가능하게 합니다.
● 결국, 모델을 만들 때 가장 중요한 것은 단순화하여 계산 복잡도를 줄여주면서도, 현실을 잘 반영하여 분제를 해결(분류, 예측, 최적화 등)할 수 있게 하는 것입니다.
● 이런 면에서 볼 때, 기계학습은 데이터를 잘 표현하는 모델을 만드는 작업입니다. 기계학습 알고리즘은 훈련용 데이터 셋을 활용하여 컴퓨터가 의사결정 프로그램을 만드는 역할을 합니다.
● 머신러닝의 지도학습은 데이터와 정답을 함께 제공하며, 패턴 분류(강아지와 고양이 구분)와 회귀 분석(6,9,13세의 키 데이터가 있을 때, 10세 때의 키 맞추기)이라는 대표적인 문제를 수행합니다.
●머신러닝의 비지도학습은 정답 없이 데이터만 제공하며, 데이터에 숨겨진 패턴을 파악하여, 입력된 데이터가 서로 유사한지 그렇지 않은지를 판별하여 알려줍니다. 비지도학습은 군집화와 차원 축소(차수 축약)이라는 대표적인 문제를 수행합니다.
● 지도학습은 데이터 전처리 및 라벨링의 작업에 굉장히 많은 시간과 비용, 인력이 들어갑니다. 반면에 비지도학습은 이러한 것에서 '상대적으로' 자유롭습니다(물론 데이터 전처리는 합니다). 또 비지도학습은 데이터 자체의 본질적인 특성이 모델링 되는데 기여하므로 일반화 성능을 끌어올려줄 수 있습니다.
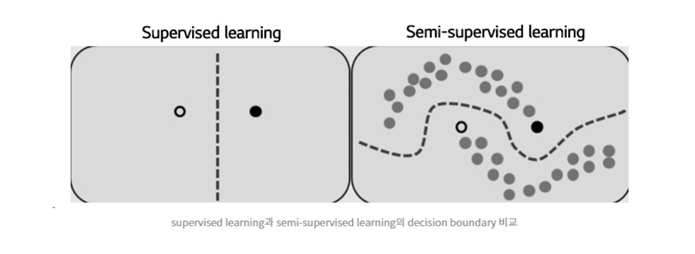
● 하지만 지도학습은 앞서서 언급했던 패턴 분류와 같은 문제에서 비지도 학습에 비해 훨씬 뛰어납니다. 아무래도 정답을 제공해주기 때문이죠.
● 아하! 그렇다면 지도학습과 비지도 학습의 장점을 섞어보면 어떨까요?
● 사실 라벨링된 데이터를 구하는 것도 참 어렵기 때문입니다. 또 구했다 하더라도 라벨링 된 데이터의 분포가 진짜 데이터의 분포 전체를 커버하지 못할 수도 있기 때문에 테스트 데이터가 들어왔을 때 잘 맞추지 못할 가능성이 큽니다(..)
● 네, 데이터를 제공할 때, 정답이 있는 데이터에 정답이 없는 데이터를 믹스하여 학습 훈련에 제공한다면(..) 모르긴 몰라도 비용절감과 패턴 분류 문제에서의 성능 향상을 기대해볼 수 있겠습니다.
● 이렇게 지도학습과 비지도 학습의 요소를 섞어서 훈련하는 방법을 우리는 준지도 학습(Semi-supervised learning) 혹은 자기주도학습(Self-supervised learning)이라고 부릅니다.
● 자기주도학습이라고 인간의 자기 주도 학습이라고 여기지는 맙시다. 알아서 학습하는 건 절대 아니니까 말이죠.
<딥러닝에서의 잠재공간 누비기>
● 딥러닝은 정형화된 데이터 뿐만 아니라 비 정형화된 데이터에 대한 분류 및 예측을 한 차원 높였습니다.
● 그 중에서도 우리는 딥러닝 내부 공간에 생성되는 잠재 공간(Latent space)에 주목할 필요가 있습니다.
● 잠재공간(Latent space)이라는 것은 뭘까요? 잠재공간은 데이터의 유사성을 기반으로 한 배치를 할 수 있는 공간입니다. 좀 더 자세히 살펴볼까요?
● 딥러닝 모델로는 Word2VecWord2 Vec을 살필 필요가 있습니다. 이 모델은 단어를 벡터로 인코딩(부호화)하는 모델이라 하여 워드투벡이라 붙여졌습니다. 워드투벡은 단어의 의미가 유사함을 판단하고 유사한 단어일수록 가까운 곳에 배치할 수 있는 잠재 공간을 형성합니다.
● 잠재공간에서는 단어의 의미 계산이 이루어집니다.
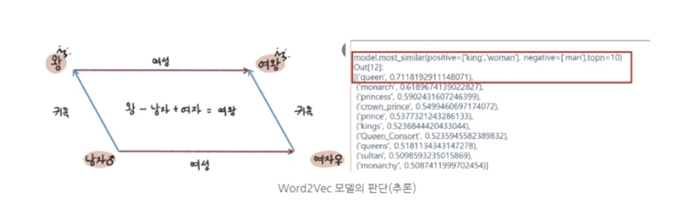
● 음(..) 학습된 모델에 왕+여자-남자와 가장 유사한 단어를 찾아달라는 말에 Queen이라는 단어가 71%의 확률로 선정되었습니다. 이러한 단어의 의미 계산과 유사도에 따른 배치가 이루어지는 곳이 잠재 공간인 것입니다.
● 의미는 추상화를 통해 발현됩니다. 그러므로 보통 신경망은 입력층에서 출력층으로 갈수록 노드의 개수가 줄어드는게 일반적입니다.
● 노드의 개수가 줄어야 데이터의 추상화된 특징벡터가 잘 담길 수 있기 때문입니다.
● 가장자리나 모서리에 보이는 일반적인 특징이 아니라, 눈 귀 코 입과 같은 종합적이고 추상적인 특징을 만들어내야 성능이 좋아지기 때문이죠.
● 신경망은 구조가 중요하며, 그 구조안에서 데이터의 학습이 이루어지므로 데이터의 특징을 뽑아내어 추상화할 수 있는 공간이 필요합니다.
● 또, 추상화하면 계산이 가능해지게 되는데 이를 처리할 공간이 필요한데, 이 공간이 딥러닝에서의 잠재공간이다라고 정리하면 좋을 것 같습니다..
● 다음에는 이미지에 대한 잠재 공간을 생성하는 오토 인코더(AutoEncoder)에(AutoEncoder) 대해 살펴보고, 딥러닝에서의 잠재 공간에 대해 추가적으로 살펴보겠습니다.
'인공지능 (AI)' 카테고리의 다른 글
| 31번째 이야기 - 모의 담금질(Simulated Annealing) 알고리즘, 경사하강법, gradient descent (0) | 2022.11.21 |
|---|---|
| 30번째 이야기 - 오토인코더, autoencoder, 경사하강법, 평균제곱오차, mse (0) | 2022.11.21 |
| 28번째 이야기 - 비선형 데이터, 신경망의 구조, 마스터 알고리즘, (0) | 2022.11.04 |
| 27번째 이야기 - 연결주의, 인공신경망, 심층 신경망, 렐루 함수, RELU 활성화 함수 (2) | 2022.11.04 |
| 26번째 이야기 - 순방향 계산, 손실함수, 오차에 대한 가중치, 기호주의 (0) | 2022.11.04 |




댓글